Knowledge base
Le Knowledge Base (KB) alimentano la pipeline RAG (Retrieval-Augmented Generation) degli agenti. Una KB e' una raccolta di documenti, pagine web, FAQ o risultati di query SQL che vengono chunkati, embeddati e indicizzati in un vector store per consentire ricerca semantica.
Lista delle KB
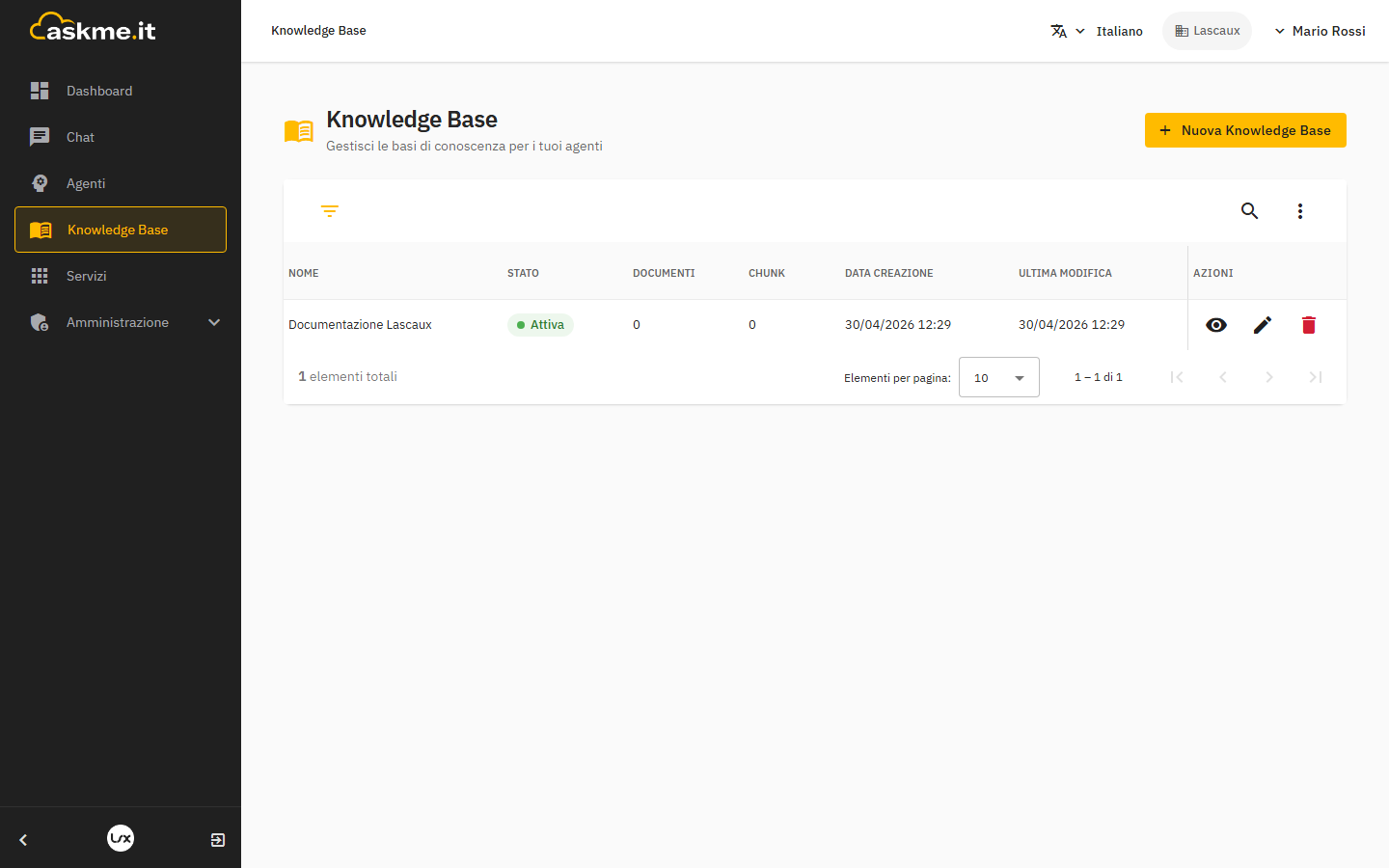
La lista mostra: nome, stato, numero di documenti, numero di chunk indicizzati.
Stati
| Stato | Significato |
|---|---|
In attesa (pending) | Creata, in attesa di indicizzazione |
In elaborazione (processing) | Chunking ed embedding in corso |
Pronto (ready) | Disponibile agli agenti |
Errore (failed) | Indicizzazione fallita; verifica i log nel dettaglio |
Le KB create automaticamente dal PDF analyzer (con flag create_kb_agent=true) sono nascoste dalla lista principale per non sporcare la vista. Restano comunque accessibili dall'agente temporaneo collegato.
Creare una Knowledge Base
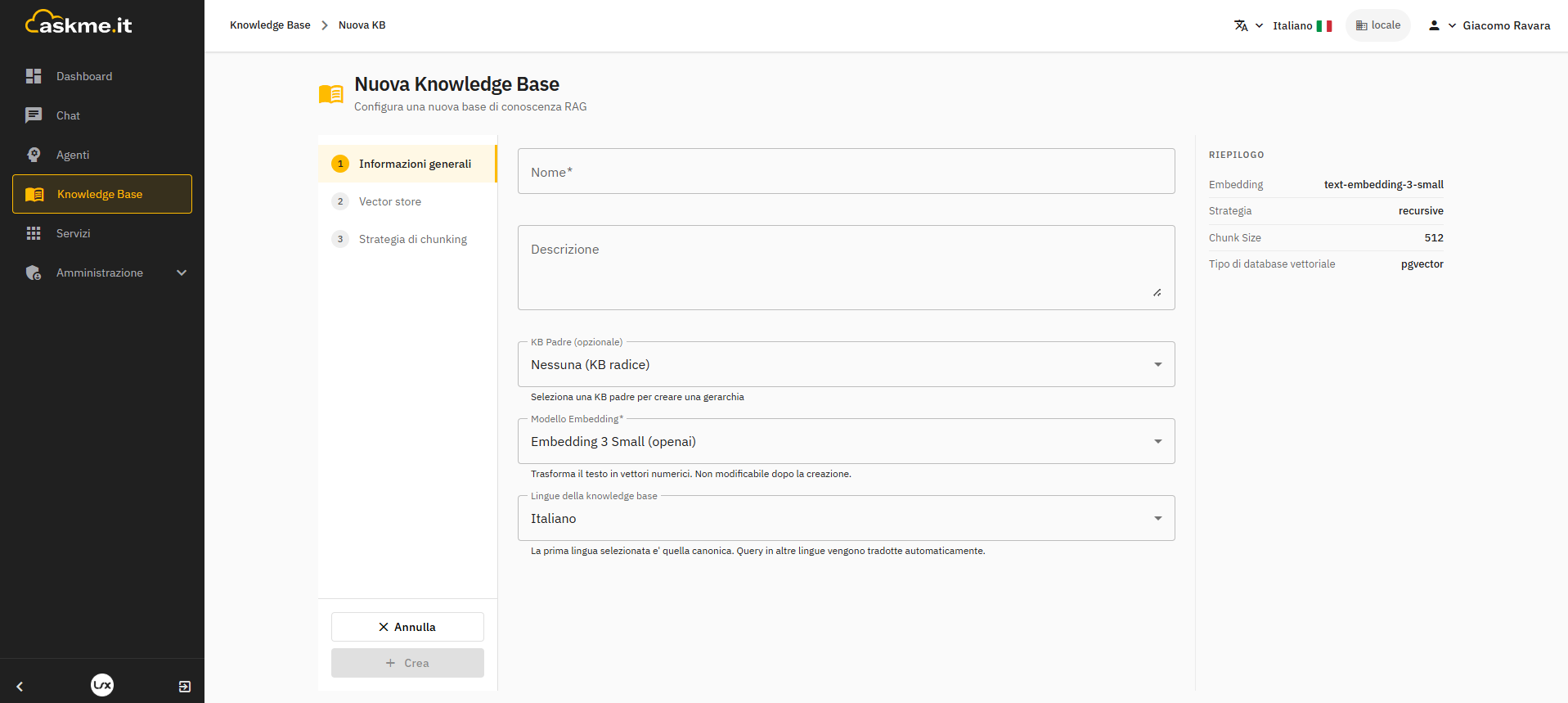
Clicca Nuova KB. Il wizard e' suddiviso in step: informazioni generali, vector store, chunking, retrieval, RAG avanzato.
Lingue della KB
Nel form puoi specificare una o piu' lingue (es. it, en, es). La prima lingua dell'elenco e' quella canonica.
A runtime la lingua della domanda dell'utente viene rilevata automaticamente. Se la lingua non e' tra quelle dichiarate dalla KB, la query viene tradotta nella prima lingua dell'elenco prima di interrogare il vector store. In caso di errore di traduzione, viene usata la query originale.
Cosi' un utente che scrive in inglese puo' interrogare una KB italiana ottenendo comunque risultati pertinenti.
Vector store
- pgvector (default) — nessuna configurazione aggiuntiva, usa l'estensione PostgreSQL integrata
- Qdrant — istanza esterna; richiede URL, API key, collection, dimensioni e (opzionale) endpoint embedding personalizzato
Chunking
- Strategia: Fisso / Ricorsivo / Semantico / Parent-Child
- Chunk size (256-2000 caratteri) e overlap (10-20% consigliato)
Retrieval
- Funzione di distanza (coseno consigliato), Top-K, soglia di similarita'
RAG avanzato
- Arricchimento contestuale — antepone titolo / sezione al chunk per migliorare la recuperabilita'
- Riscrittura query — modalità
semplice(singola riformulazione) omulti-querycon fusione RRF (configurabile sull'agente, vedi Agenti — Step 4)
Dettaglio KB
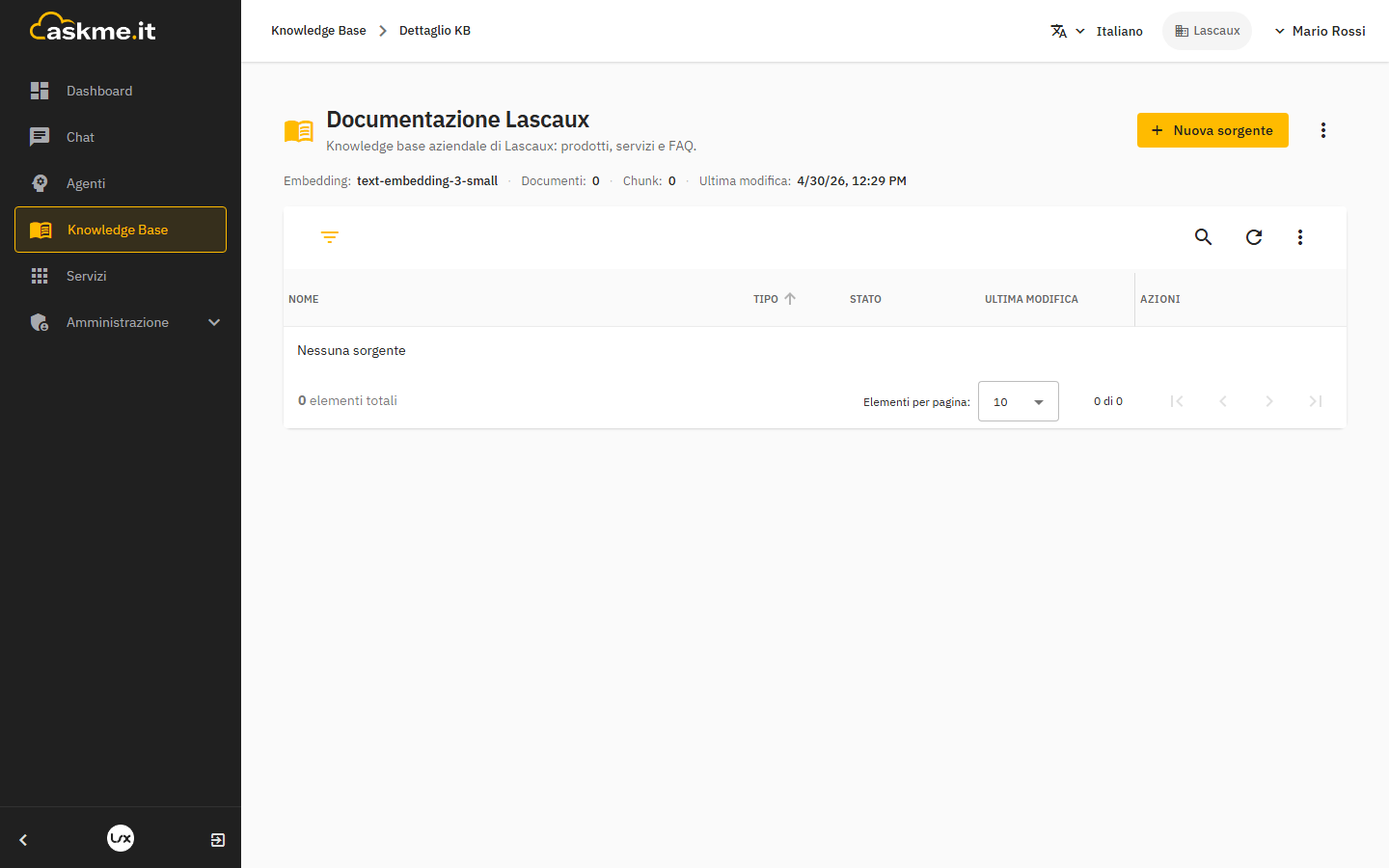
Le sorgenti sono organizzate per tipo:
- Documenti — file caricati (PDF, DOCX, TXT, MD)
- Web — pagine acquisite tramite scraping
- FAQ — domande/risposte editoriali
- Database — query SQL su DB esterni
Filtri rapidi
In alto: Tutti / Indicizzati / Bozza-In attesa / Errori / Esclusi / Recenti (7 giorni).
Visibilita' citazioni per-sorgente
Ogni sorgente ha un toggle Mostra nelle citazioni (icona occhio aperto/chiuso):
- Disattivato — i chunk continuano a contribuire al contesto (retrieval) ma la sorgente NON appare nella lista "Fonti" mostrata all'utente in chat
- Attivato (default) — la sorgente e' visibile sia nel retrieval sia nelle citazioni
Usa questa funzione quando un documento contiene contesto interno o riservato che vuoi sfruttare ma non rivelare agli utenti finali (es. politiche commerciali, prezzistica interna, note operative).
Aggiungere sorgenti
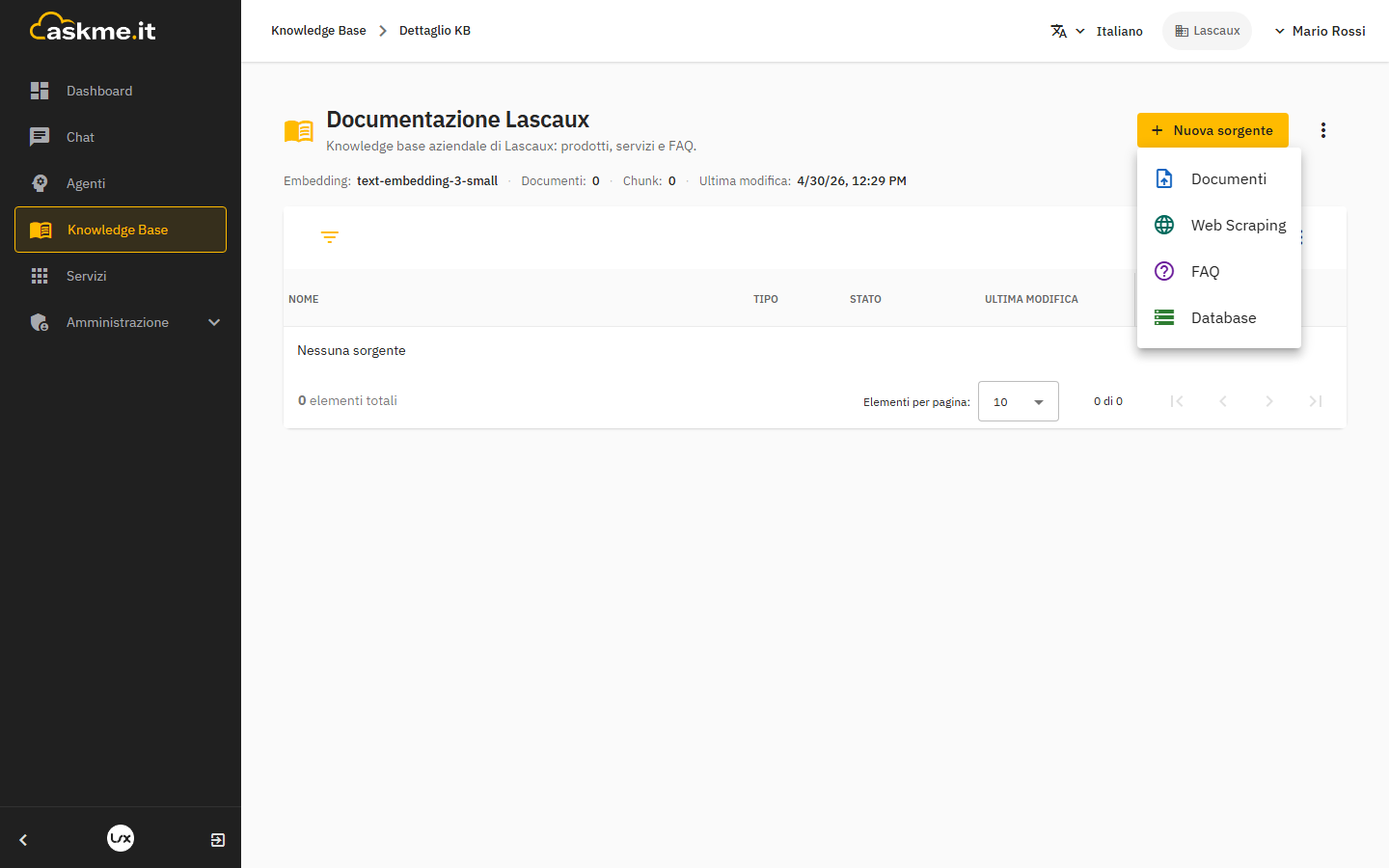
Clicca Nuova sorgente e scegli il tipo.
Documenti (upload)
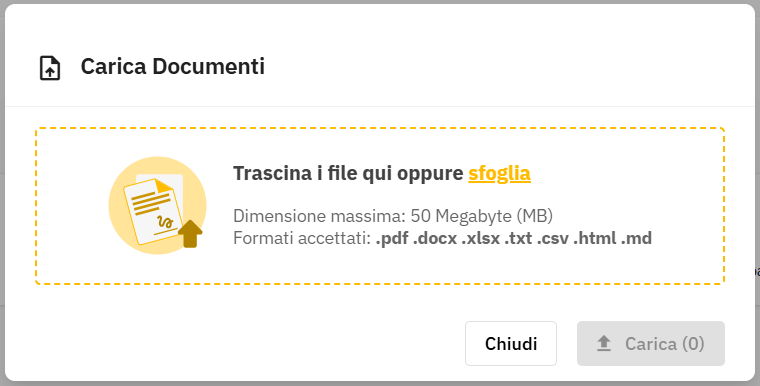
- Trascina i file (PDF, DOCX, TXT, MD) o clicca Sfoglia
- Opzionali: Priorita' (Bassa/Media/Alta), Categoria, Lingua
- Carica — chunking ed embedding partono in background
URL singolo
Inserisci l'URL e la profondita' di crawling (0 = solo pagina indicata, >0 = segui link interni). Sono disponibili opzioni di rendering Playwright per siti JavaScript-heavy.
Sitemap / scraping
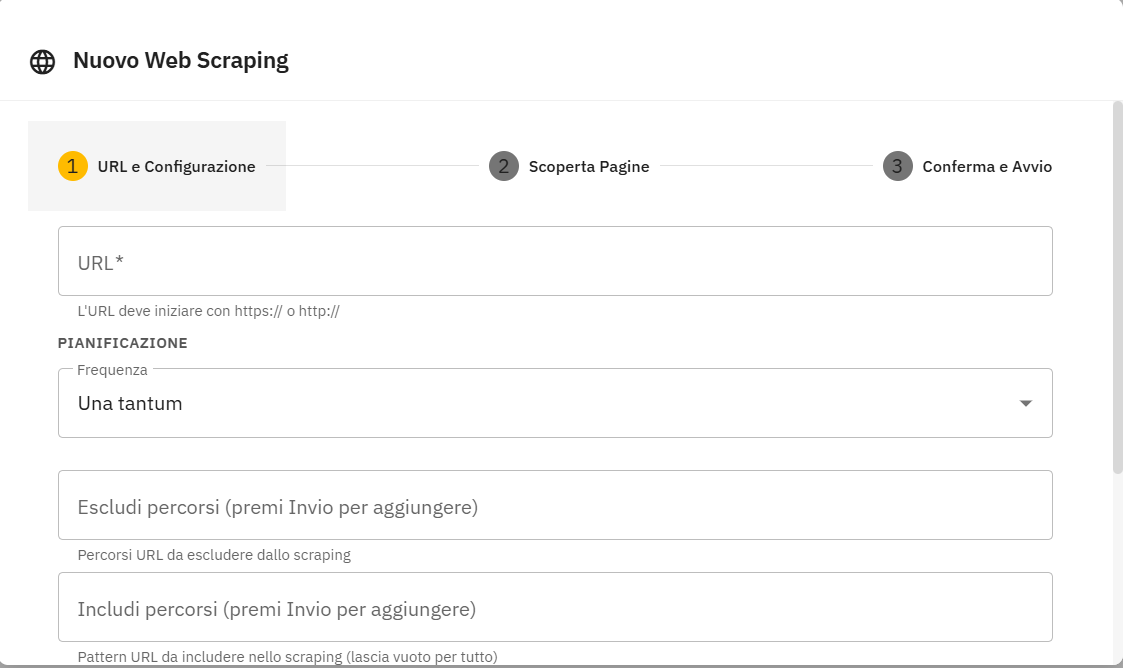
- Inserisci l'URL del sito
- La piattaforma cerca automaticamente la sitemap; in alternativa fa crawling
- Vedi la lista delle pagine trovate, seleziona/deseleziona quelle che vuoi acquisire (le pagine duplicate o vuote sono pre-deselezionate)
- Conferma e avvia: una progress bar mostra l'avanzamento
Pianificazione: una tantum, giornaliera, settimanale o mensile (con specifica di giorno e ora).
Feed RSS / Atom
Inserisci l'URL del feed (es. .rss, .atom, /feed, oppure un endpoint che restituisce application/rss+xml o application/atom+xml): il sistema rileva automaticamente il formato e parsa le entries.
Database query
- Configura connessione: tipo (PostgreSQL, MySQL, MSSQL, SQLite), host, porta, database, schema, utente, password
- Le credenziali sono cifrate at-rest nel database della piattaforma
- Specifica tabella o query SQL personalizzata
- Clicca Preview per vedere un'anteprima delle prime righe restituite
- Test connessione e poi Salva
- Esegui sync per la prima sincronizzazione (e successive a richiesta)
- Cancella cronologia rimuove le esecuzioni precedenti senza eliminare la connessione
FAQ
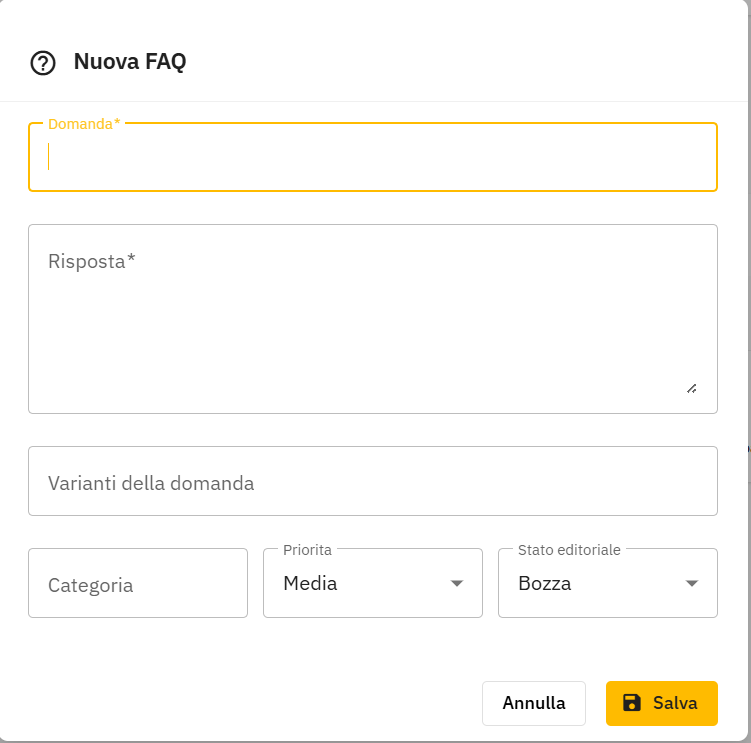
- Domanda, Risposta, Categoria, Priorita' (Bassa/Media/Alta)
- Varianti della domanda — formulazioni alternative per migliorare il retrieval
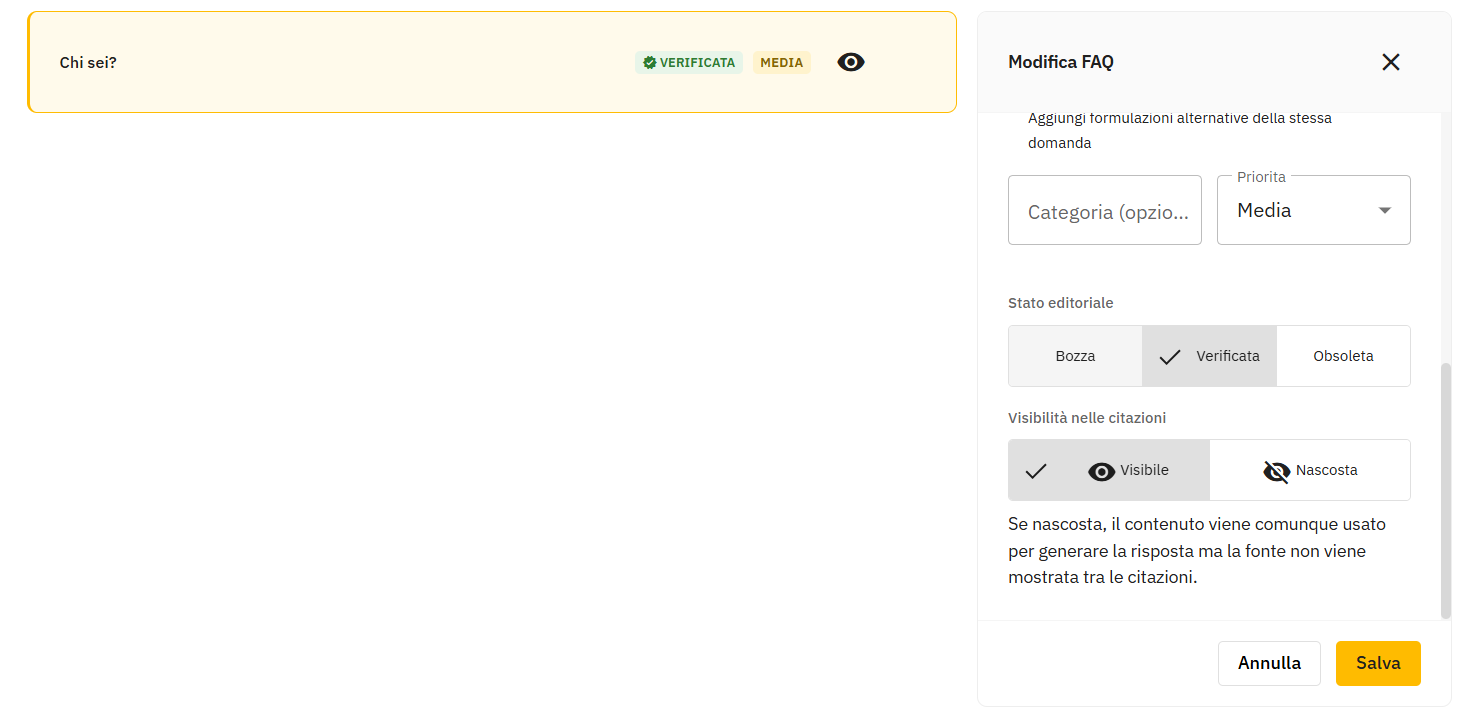
- Stato editoriale: Bozza / Verificata / Obsoleta — imposta sempre Verificata per le FAQ pronte all'uso; solo le FAQ verificate sono considerate attendibili dagli agenti
- Importa in blocco da CSV o JSON (template scaricabili disponibili)
Esportare una KB
Pulsante Esporta KB nella pagina di dettaglio: scarica un archivio ZIP con documenti e configurazioni.
Qualita' e cronologia
Nella pagina di dettaglio trovi due tab dedicati:
- Stato e Qualita' — documenti totali, indicizzati, in errore, numero di chunk, token medi per chunk, pagine web acquisite. Riepilogo dei parametri retrieval, chunking, embedding
- Cronologia — log eventi: caricamento, eliminazione, scraping, sync DB, modifiche di configurazione
Best practice
- Una KB per dominio funzionale — separa documentazione prodotto, FAQ commerciali, policy interne in KB distinte e abbinale agli agenti giusti
- Multilingua quando serve — dichiara tutte le lingue effettivamente presenti nei contenuti per evitare traduzioni superflue
- Nascondi le citazioni di documenti riservati — sfrutta il toggle per documento, non duplicare i contenuti
- Pianifica gli scraping — per portali che cambiano spesso programma uno scraping settimanale per mantenere la KB allineata
- Verifica le risposte incerte — convertile in FAQ direttamente dal dettaglio agente